Дорогой читатель, перед вами притча о том, как разные подходы к организации работы отражаются в степени удовлетворенности заказчика.
Стояло лето 2008 года, точнее июль. Так случилось, что три вечера подряд я ужинал в трех разных ресторанах. В каждом из них по-разному решали вопрос с пополнением моего стакана воды и это привлекло мое внимание.
Режим «по прерыванию»
Во вторник вечером я ужинал в Friendly’s. Если вы не знаете, Friendly’s — это сеть ресторанов средней категории, нацеленная на семьи с детьми. Три таких ресторана находятся недалеко от места, где я живу в Нью-Джерси. Обычно, там работают ученики старших классов и, скорее всего, это их первая работа.
Пока мы ужинали, официантка пополняла наши стаканы с водой, как только мы ее об этом просили. Она слышала нашу просьбу, подходила, забирала пустые стаканы на кухню, а затем возвращалась с наполненными. Она определенно считала, что хорошо нас обслуживает: она быстро выполняла то, что мы просили.
Но, хотя она так думала, мы воспринимали это по-другому. Нужно было долго ждать, чтобы она нас заметила. Проходило немало времени, прежде чем мы могли попросить что-то, особенно если она принимала заказ у большой семьи с детьми или у колеблющихся взрослых. Она считала, что немедленно реагирует на наши запросы; мы же испытывали проблемы с тем, чтобы добиться обслуживания.
Результат:
- Лучший вариант: официантка была доступна немедленно и мы быстро получали воду.
- Худший вариант: мы ждали 5–10 минут, пока она к нам подойдет, после чего получали воду быстро. Но пока она наполняла наши стаканы, мы были без воды, которая еще в них оставалась.
- В общем: так себе.
Пакетный режим с прерываниями
В среду я ужинал в модном ресторанчике, который находится в Нью-Йоркском районе Адская кухня. Название района отражает дурную славу, которую он имел до конца 80-х годов прошлого века. Позднее он был облагорожен и сейчас там располагается множество отличных ресторанов. Культура работы официантов в Нью-Йорке имеет очень высокие стандарты. Эти люди усердно работают, мало получают и живут в местах, где стоимость жизни очень высока. Чаевые в этом городе начинаются с 20% совсем неспроста. С тех пор как я начал работать в Нью-Йоркском офисе Гугл, я нашел тут много отличных ресторанов.
В этом ресторане к вопросу пополнения стаканов с водой подходили по-другому. Периодически официантка отрывалась от приема и разноса заказов, и обходила свою часть зала с кувшином воды, доливая ее во все ненаполненные стаканы.
Если кто-нибудь просил воду скорее, она выносила кувшин, наполняла стакан этого человека, а потом обходила остальную часть зала.
Другими словами, она периодически выполняла пакетный процесс, а иногда этот процесс вызывался по прерыванию от клиента.
Результат:
- Лучший вариант: вода доливалась без просьбы.
- Худший вариант: также, как и в Friendly’s, но стаканы всегда были у нас на столе и меньше нужно было мыть посуды.
- В общем: иногда мы ждали, но обычно все было без задержек и напоминаний. В целом, очень хорошо.
Режим делегирования
Вечер четверга я провел за ужином в Skylight Diner, расположенном в Нью-Йоркском районе Клинтон. Skylight — это греческая закусочная. Есть несколько вещей, которые нужно знать о греческих закусочных, типичных для Нью-Йорка и Нью-Джерси. Во-первых, они называются «греческими» не потому, что там подается греческая кухня, а потому, что их владельцы обычно греческого происхождения. Нью-Йорк — это город иммигрантов и это одна из тех особенностей, которые делают его таким замечательным. Во-вторых, меню в этих заведениях огромные: страница за страницей следуют блюда от гамбургеров и пасты до морепродуктов и соте. В некоторых даже есть греческие блюда. В-третьих, блюда обычно отличные, а порции — поразительно большие. Наконец, если вы слышите «закусочная» и представляете страшненький фастфуд, вы ошибаетесь на 100%. Чтобы искупить свою ошибку, сходите в такую закусочную, когда голодны. Очень голодны.
Официантки в Skylight никогда не пополняли наши стаканы с водой, это была обязанность их помощников — басбоев. Они постоянно обходили столы, забирая пустые тарелки и наполняя наши стаканы водой. Если стакан с водой у кого-то все-таки пустел и он обращался к официантке, то она подзывала ближайшего басбоя и говорила: «Más agua aquí».
Это сила делегирования или, можно сказать, автоматизации.
Результат:
- Лучший вариант: вода доливалась без просьбы.
- Худший вариант: вода доливалась, сразу после просьбы.
- В общем: практически всегда был лучший вариант.
Если в закусочную приходила большая компания, то басбои просто оставляли графин с водой у них на столе и процесс доливания воды в стакан становился само-обслуживаемым.
Результат:
- Лучший вариант: вода доливалась по необходимости.
- Худший вариант: ждать, пока нальют новый графин с водой.
- В общем: обычно как в лучшем варианте.
Организация работы
Способы организации работы системных администраторов разнятся так же сильно, как и подходы к наполнению стакана воды в ресторанах.
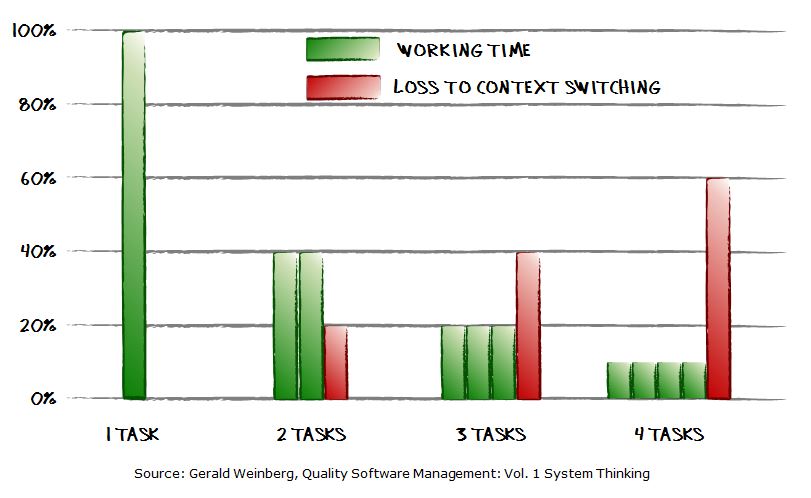
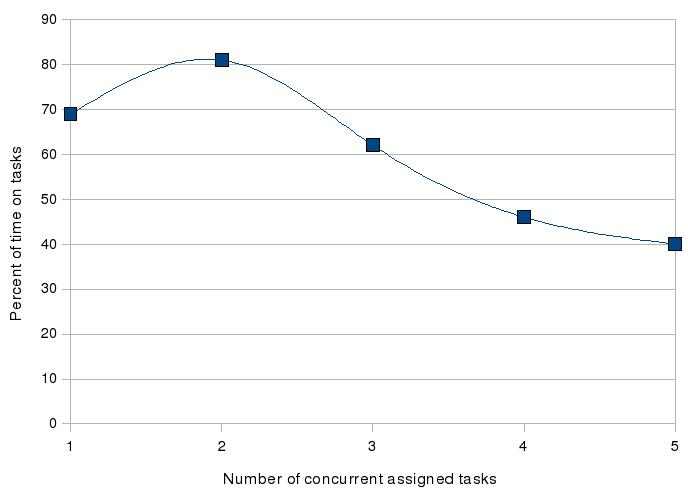
Когда мы только начинаем работать системными администраторами, мы работаем “по прерыванию”. Кто-то просит помочь или что-то сделать, мы помогаем или делаем. Нам кажется, что мы отлично работаем, потому что сразу реагируем на запросы. Проблема в том, что мы не учитываем, сколько наши клиенты ждут возможности нас попросить о чем-то.
В напряженный день от нас нереально добиться помощи. Мы гордимся тем, как хорошо справляемся с некоторыми задачами, но в среднем наши показатели ужасны. Хуже всего то, что мы загоняем себя: прерывания управляют нашим временем и мы мало что можем с этим сделать.
Ситуация улучшается, когда мы начинаем работать в пакетном режиме. Становится лучше наш средний показатель. Поскольку мы перестаем реагировать на пользовательские запросы немедленно, мы переживаем, что не всегда можем предоставить отличный сервис на некоторых задачах. Но правда заключается в том, что возможность предоставить идеальный сервис очень редка и, к тому же, мы редко учитываем, сколько человек прождал, прежде чем смог нас попросить о чем-то. Так что именно средний показатель очень важен.
Есть несколько подходов, позволяющих переключится из режима работы по прерыванию в пакетный режим.
Когда нас отрывают с какой-то новой задачей, то вместо того, чтобы сразу хвататься за нее, надо взвесить имеющиеся варианты. Выслушайте запрос. Пауза. А теперь подумайте, что лучше с ним сделать: записать, делегировать или сделать?
Можно записать запрос в свой список задач или открыть тикет в системе запросов.
Можно делегировать его, если есть разделение сфер ответственности и администраторы специализируются в разных областях.
Если же запрос действительно срочный или же он попадает в вашу сферу ответственности, тогда можно за него взяться немедленно. Но это должно быть последним вариантом, всегда лучше записать запрос, чтобы выполнить его после более приоритетных задач или в пакете с аналогичными запросами.
Задавайте вопросы
Раньше я считал, что все запросы срочные. Теперь я всегда спрашиваю «когда вам это нужно будет?». Удивительно, как много запросов, которые звучат неотложными, оказываются не такими и срочными, если только об этом спросить. «Да я на днях лечу в Бостон, сможешь это сделать до моего возвращения?» или «Он выходит на работу 18-го октября, нужно сделать до этого момента».
Поразительно, как часто мы забываем задать этот вопрос.
Возможность записывать задачи зависит от наличия места, где их можно записать. Один из способов — это список задач в ежедневнике (мои рекомендации приведены в [1]). Однако, в дополнение, очень важно иметь систему отслеживания запросов, которая позволяет пользователям ставить задачи не отрывая вас от текущих задач. Существует множество типов таких систем автоматизации службы поддержки или отслеживания запросов. Они бывают как с открытым исходным кодом, такие как Request Tracker [2] и OTRS [3], так и платные.
Когда запросы находятся в такой системе, становится возможным хранить всю коммуникацию, связанную с конкретной задачей, в одном месте; пользователи могут узнать статус задачи, никого не отрывая от работы; повышается эффективность работы системных администраторов (упрощается передача задач коллегам); наконец, руководство может неназойливо наблюдать за работой СА и генерировать статистические отчеты, которые нужны для их работы.
Кроме того, система отслеживания запросов позволяет лучше соблюдать приоритетность задач. Когда задач становится много, мы можем легко отобрать в системе высокоприоритетные и работать над ними в первую очередь, например отсортировав задачи по дате, к которой они должны быть выполнены.
Аварийные ситуации
Единственный тип запросов, требующий немедленной реакции, это сообщения об аварийной или нештатной ситуации. К сожалению, есть пользователи, для которых все является аварийной ситуацией. Решить такую проблему можно, определив в письменном виде, что является аварийной или нештатной ситуацией. Такой документ должен быть утвержден на уровне руководства организации. В газете, например, аварийной ситуацией есть все, что непосредственно делает невозможным выход завтрашнего номера в срок, но не более того. Нештатной ситуацией в институте может быть что-то, что мешает проведению лекции в запланированный день (но только, если преподаватель предварительно предупредил о ней).
Любой шеф-повар должен иметь в своем распоряжении инструменты для своей работы: плиту, кастрюли и сковородки. Так же и системный администратор должен иметь свои инструменты — систему учета запросов и утвержденное определение аварийной ситуации.
Варианты пакетных режимов
Свою работу в пакетном режиме можно организовывать по-разному.
Можно делать все связанные задачи в пакете. Например, для того, чтобы внести изменения в DNS, нужно открыть панель управления или зайти на определенный сервер и открыть файл в редакторе. Добавив необходимую информацию, мы можем поискать и выполнить другие запросы, связанные с DNS. Или можно оставлять все несрочные запросы, связанные с DNS, для выполнения ежедневно в 4 часа.
Можно собирать пакет задач по местонахождению: отобрать все запросы, требующего физического посещения здания №47 и сделать из все за один визит.
Можно собрать в пакет все запросы от одного конкретного пользователя. Часто, когда мы перегружены, бывает очень приятно, несмотря на десятки или сотни тикетов в очереди, сделать хотя бы одного пользователя счастливым.
Если работа над запросами требует коммуникации с пользователем, часто бывает быстрее позвонить человеку и пройтись по его запросам, закрывая их по ходу разговора. Еще лучше, выполнить все запросы, не требующие разговора с ним, а потом позвонить и закрыть оставшиеся. Пользователь тогда сначала получит почту о закрытых запросах, а потом, вдруг зазвонит телефон и с ним закроют оставшиеся запросы. Ощущение, как-будто выиграл в лотерею.
Кроме того, это еще и более эффективный подход. Установления канала обмена информацией с пользователем требует времени (найти его, назначить встречу, дойти до его рабочего места, или открыть окно мессенджера). Сделав это один раз, стоит выполнить и остальные запросы пользователя в пределах этой коммуникации или, хотя бы, сообщить о статусе их выполнения.
Также я советую собирать запросы одного типа для выполнения в определенные дни. Например, активация сетевых розеток может происходить по вторникам и четвергам. Вместо ежедневной замены кассет в стримере, установите систему автоматической замены лент, требующей загрузки кассетами раз в неделю. Система по-больше, позволит делать это раз в месяц, а большая ленточная библиотека может вообще устранить задачу как таковую.
Делегирование и специализация
Системные администраторы специализируются и делегируют задачи аналогично официантам в Skylight Diner. Делегирование сильно упрощается, если задачи документированы. Но не надо думать, что документация должна быть изощренной и сложной, часто бывает достаточно простого списка шагов на вики.
Специализация становится возможной только с ростом компании. Как правило, отдел ИТ в маленькой фирме начинается с одного человека, отвечающего за всё.
Спустя некоторое время нанимается другой специалист и, теперь, они вдвоем несут на себе всю тяжесть ИТ. Переместимся на несколько лет вперед и мы обнаружим ИТ-отдел из 10 человек, которые пытаются отвечать за всё. Когда же они должны начать специализироваться? Вероятно, после второго или третьего человека принятого в команду. Это сильно зависит от организации, поскольку в разных организациях требуется разная специализация. Обычно люди специализируются в областях, где нужны специфические знания. Если есть потребность в большом, постоянно растущем хранилище данных, некоторые люди могут специализироваться на хранилищах. Даже в маленьких командах есть человек, который лучше всех разбирается в сетях и отвечает за Интернет-шлюз с фаерволом.
При наличии надлежащей документации, каждый в команде может выполнять базовые рутинные задачи, связанные с инициализацией (т.н. «добавление, изменение и перемещение»). Нестандартные операции (масштабирование сервиса, оптимизация и новая функциональность) остаются в ведении специалиста.
Другими словами, каждый системный администратор в команде должен уметь добавить машину в сеть, обновить DNS и т.п. Специалист же, знает как и отвечает за создание новый подсети и зоны в DNS или изменение правил в фаерволе.
Документированные процедуры гораздо проще оптимизировать и автоматизировать. В таком случаем, мы можем выбрать какую часть процесса нужно автоматизировать (какие шаги из списка на вики) или автоматизировать весь процесс.
Автоматизация
Графин с водой на столе у клиентов превращает обременительный процесс пополнения стаканов с водой в функцию самообслуживания. В системном администрировании часто проще всего автоматизировать задачи создания учетных записей или предоставления доступа к ресурсам. Возмем, к примеру, сервис VPN. Настройка сервера — задача одноразовая и смысла ее автоматизировать нет. В то же время, добавление новых учетных записей — процесс повторяемый, а потому легко автоматизируемый.
Сперва можно автоматизировать процесс так, чтобы системный администратор мог легко активировать или дезактивировать доступ для одного пользователя. Такой инструмент освободит время администратора для других задач. Следующим шагом должно стать создание функции самообслуживания: веб-страница, где пользователь может запросить доступ одним кликом. Этот запрос должен быть одобрен ответственным администратором, после чего система сама автоматически выполнит необходимые действия по активации доступа. Некоторые люди могут быть предварительно одобрены, например, пользователи в LDAP-группе «Engineers». Или же только люди из LDAP-группы «Visitors» требуют ручного одобрения администратором. Теперь у вас есть инструмент, который не только освобождает ваше время, но и позволяет пользователям самим решить свою задачу.
В ресторанах возможностей для автоматизации гораздо меньше, чем у системных администраторов. Да, они могут построить роботов, которые будут принимать заказы и разносить еду. Это было бы здорово. Однако, человеческий аспект — это именно то, что мы так любим в ресторанах. Обслуживание — это роскошь. И хотя в ресторанах не так много возможностей для автоматизации, они могут улучшать свои процессы с помощью пакетного подхода и лучшей организации работы.
У нас, как системных администраторов, есть много возможных подходов к нашей работе: по прерыванию, пакетный, делегирование, автоматизация, самообслуживание.
Какие из них используете вы?
О чем стоит подумать
- В каком режиме вы работали последнюю неделю: по прерыванию, пакетном, делегирования, автоматизации или писали системы самообслуживания?
- Какие три задачи на работе вы можете выполнять в пакетном режиме?
- Когда кто-то делает запрос, как вы определяете насколько он срочен?
- Какие есть специализации в вашей команде? Являются ли они официально признанными?
- Как бы вы реорганизовали то, как делаете свою работу? Какое влияние это окажет на вас? На ваших пользователей?
- Как бы вы реорганизовали работу своей команды или ИТ-отдела? Что в результате станет лучше, а что хуже для вас и ваших пользователей?
- Отвечая на вопросы 5 и 6 вы предложили много изменений. Какие из них будут иметь наибольшее влияние? А какие сулят наиболее быстрый результат?
Ссылки
[1] Thomas A. Limoncelli, Time Management for System Administrators (O’Reilly Media, 2005).
[2] RT: Request Tracker: http://www.bestpractical.com
[3] OTRS: http://www.otrs.org




 Понятно, что эти советы не ограничиваются ethernet-сетями. Сети хранения данных подвержены тем же проблемам, возможно, даже с более тяжелыми последствиями для ваших данных. Все, известные мне, технологии сетей хранения данных поддерживают функциональность
Понятно, что эти советы не ограничиваются ethernet-сетями. Сети хранения данных подвержены тем же проблемам, возможно, даже с более тяжелыми последствиями для ваших данных. Все, известные мне, технологии сетей хранения данных поддерживают функциональность  На картинке выше изображен естественный враг сетевых администраторов. Это оптико-искательный экскаватор, и одного такого достаточно, чтобы разрушить все ваши тщательно продуманные планы. Одним легким движением рычага, его зияющая пасть разрывает самые тяжело бронированные оптические кабеля и лишает интернета целые кварталы города. Пощады не будет ни для какого провайдера. Мыльте веревку.
На картинке выше изображен естественный враг сетевых администраторов. Это оптико-искательный экскаватор, и одного такого достаточно, чтобы разрушить все ваши тщательно продуманные планы. Одним легким движением рычага, его зияющая пасть разрывает самые тяжело бронированные оптические кабеля и лишает интернета целые кварталы города. Пощады не будет ни для какого провайдера. Мыльте веревку.