Рисунок 1. Физическая диаграмма КВД
Автор: © Алан Робертсон (Alan Robertson)
Опубликовано: LinuxMagazine, November
2003
Перевод: © Иван Песин, Russian Linux Gazette, Сентябрь 2004
Диаграммы: © LinuxMagazine
Оригинал: http://www.linux-mag.com/2003-11/availability_01.html
Если вы системный администратор, то с вами такое уже случалось: вы как раз заказали обед, когда заверещал ваш пейджер. Обед сегодня отменяется. Или другой пример: сервер упал, а системный администратор исчез. Вы срываете сроки, потому что некому восстановить критически важную систему.
Кластера высокой готовности (High-availability (HA) clusters) позволяют значительно уменьшить время простоя системы и, учитывая, что обработка отказов происходит быстро и в автоматическом режиме, системные администраторы могут закончить обедать, а пользователи -- свою работу. Администраторы довольны, пользователи довольны, даже тупоголовые менеджеры [прим.ред. -- генетически изменённая, возможно небелковая форма жизни, населяющая нашу планету. ;-)] довольны, ведь уменьшение времени простоя экономит деньги.
Поскольку "высокая готовность" разными людьми понимается по-разному, мы будем говорить о кластерах высокой готовности (КВГ) Кластер ВГ представляет собой набор серверов, которые совместно работают для предоставления определенных сервисов. Сервисы принадлежат не конкретному серверу, а всему кластеру. Если происходит сбой одного из серверов, его функции автоматически переходят к другому серверу кластера.
Хотя системы высокой готовности не могут полностью устранить отказы, они позволяют максимально минимизировать время простоя. И тогда этот отказ может пройти незаметно, либо его проявление спишут на что-либо иное, например "проблемы" с Internet. При правильной настройке системы высокой готовности работают как волшебники, у которых руки быстрее глаз. Действительно, корректно спроектированный, настроенный и правильно управляемый кластер добавляет "девятку" к доступности и уменьшает время простоя на 90%. На врезке "Магия девяток", расшифровано значение количества "девяток".
Доступность сервиса обычно измеряется количеством "девяток". Если сервер работает 90 процентов времени, то его доступность -- это одна девятка. Если время работы достигает 99 процентов -- доступность равна двум девяткам и т.д. Если привести эти "девятки" к обычному времени простоя в год, получится следующая таблица:
| Пп | Доступность в 9-ках | Время простоя в год |
|
1 |
90.0000% |
37 дней |
|
2 |
99.0000% |
3.7 дней |
|
3 |
99.9000% |
8.8 часов |
|
4 |
99.9900% |
53 минуты |
|
5 |
99.9990% |
5.3 минуты |
|
6 |
99.9999% |
32 секунды |
Даже если вы изначально используете ненадежную операционную систему, ненадежное программное обеспечение и устанавливаете его на аппаратное обеспечение "со странностями", хорошее программное обеспечение КВГ ощутимо улучшит ситуацию. В идеале вы сможете добиться даже "трех девяток". А если вы начнете с серьезного серверного аппаратного обеспечения, добавите к этому стабильное ядро Linux и надежное программное обеспечение, прибавьте к этому хорошо обученный персонал и отработанные процедуры поддержки, вам обеспечены лучшие результаты. В этом случае можно говорить уже о пяти девятках и более.
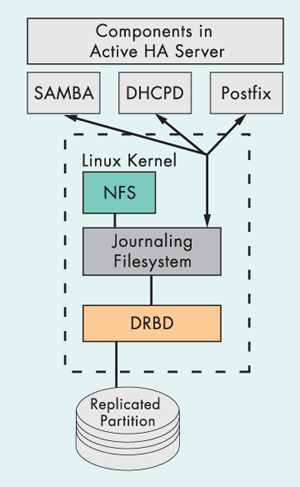
Давайте теперь разберемся как настраивать и запускать сервер высокой готовности. Наш пример (основанный на личном кластере автора, предназначенном для разработки) обеспечивает четыре сервиса ВГ: NFS, Samba, DHCP и Postfix (почтовый сервер). Работает он на двух серверах архитектуры х86, схема соединения которых приведена на рисунке 1. Система может использоваться для совместной разработки программного обеспечения, хранения документов и электронной почты. Здесь можно хранить и музыкальные файлы. [Прим.ред. Если, конечно, RIAA не в курсе происходящего. :-)] А поскольку это система ВГ, то в случае краха одного из серверов, или останова для проведения профилактических работ, музыка будет просто продолжать играть. Высокая доступность почты и "пуленепробиваемый" музыкальный центр -- что еще нужно ?
|
|
|
Рисунок 1. Физическая диаграмма КВД |
Сервера, изображенные на рисунке 1, это х86 системы с операционной системой SuSE Linux Enterprise Server 8 (SLES8) с двумя IDE дисками: на одном размещен загрузочный раздел и сама система, на другом -- раздел /home, размером 80Гб. Выбор в пользу SLES8 был сделан в связи с тем, что он поставляется со всем необходимым ПО достаточно свежей версии.
Пакет Heartbeat (сердцебиение - прим.пер.) используется для обнаружения сбоев и управления ресурсами кластера. Пакет DRBD обеспечивает постоянную синхронизацию раздела /home на обеих системах. DRBD можно представлять как RAID1 (зеркалирование) через сеть.
Это минимальная конфигурация сервера высокой надежности с общими данными. Для мощных (с критическими запросами к скорости работы с дисковой подсистемой) систем с быстрыми дисками, выделенный канал должен организовываться на основе гигабитного соединения. Стоимость гигабитных сетевых карт в настоящее время невелика и общая стоимость решения останется низкой. Насколько низкой -- это уже зависит от используемого серверного аппаратного обеспечения.
|
|
|
Рисунок 2. |
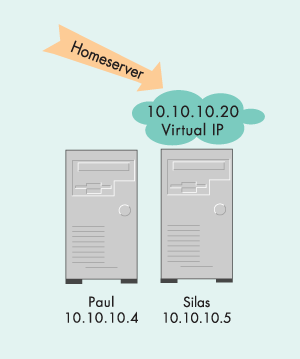
Другой способ представления системы -- это схема взаимодействия компонентов. Она проиллюстрирована на рисунке 2.
КВГ предназначены для защиты вашей системы от сбоев. Поэтому на этапе разработки КВГ важно искать одиночные точки отказа (single points of failure, SPOFs). Если в архитектуре системы существуют единичные элементы, отказ которых приводит к отказу всего кластера -- это одиночная точка отказа. Средство от одиночных точек отказа -- избыточность. Вообще, есть "правило трех И высокой готовности": избыточность, избыточность, избыточность. Если это звучит избыточно, то так оно и должно быть.
Рассмотрим системную архитектуру нашего примера. Мы видим избыточность в серверах, источниках бесперебойного питания, дисках и пр. Все это позволяет КВГ работать эффективно.
Данный пример не имеет внутренних одиночных точек отказа. Вне зависимости от того, что выйдет из строя в кластере, система продолжит функционировать. И хотя отказ репликационного канала приведет к невозможности синхронизации данных, это не вызовет отказа всего кластера, значит это не одиночная точка отказа. (В нашем примере мы рассматриваем реплицирующую систему, однако часто используются и разделяемые диски. Плюсы и минусы каждого варианта рассматриваются во врезке "Разделяемые диски и дисковая репликация"). Как можно понять из схемы, даже физическое уничтожение первичной системы не повлияет на работоспособность кластера и он продолжит функционировать.
Пакет DRBD реплицирует данные между двумя дисками любого типа и реализует очень недорогое хранилище без одиночных точек отказа. Однако требования к хранилищу увеличены в два раза, а сама система иногда подвержена длинным ресинхронизациям после сбоев. Кроме того, в некоторых задачах будет ощущаться снижение производительности дисковой подсистемы.
Для многих серьезных приложений эти неудобства критичны. В таких случаях применяются разделяемые диски. Это могут быть дисковые массивы RAID с несколькими подключениями, двойные контроллеры RAID (например, IBM ServeRAID), разделяемые диски с интерфейсом fiber-channel, высокоуровневые хранилища класса IBM Enterprise Storage Server или другие EMC-решения высокого уровня. Эти системы сравнительно дороги (начиная от $5K до миллионов долларов). Однако они не страдают снижением производительности и необходимостью ресинхронизации.
Но лишь в наиболее дорогих решениях нет внутренних одиночных точек отказа.
|
|
|
Рисунок 3: Обычная конфигурация КВГ |
Программное обеспечение КВГ следит за состоянием серверов в кластере, обычно используя механизм "сердцебиения". Этот механизм немного напоминает своей работой процесс Linux init, но для всего кластера. Он отвечает за запуск и останов сервисов, таким образом, что каждый сервис в один момент времени выполняется где-то в кластере. Один из наиболее популярных пакетов ПО для КВГ, который используется в нашем примере, называется Heartbeat.
Heartbeat использует скрипты аналогично стандартному init для запуска и останова сервисов. Управление ресурсами происходит на основе групп. Ресурсы одной группы всегда выполнятся на одной и той же системе в кластере. В дополнение к обычным скриптам сервисов (как nfsserver и dhcpd), Heartbeat управляет IP адресами с помощью скрипта IPaddr. Группы ресурсов задаются в конфигурационном файле /etc/ha.d/haresources, что будет описано ниже.
Как указывалось выше, DRBD это пакет для репликации дисков, который обеспечивает передачу каждого записанного на первичный диск блока данных ко вторичному диску. Т.е. на уровне DRBD выполняется обычное зеркалирование данных с одной машины на другую. Первичная система задается с помощью утилиты командной строки. На уровне Heartbeat, DRBD представляет собой ресурс (он называется datadisk), который необходимо запускать или останавливать (делать первичным или вторичным) по мере надобности.
|
|
|
Рисунок 4. Сбой в системе ВГ |
Для кластера из двух нод, предоставляющего сервисы на одном IP адресе, необходимо три IP адреса: по одному для каждой системы в кластере для административных задач, и один для доступа ко всему кластеру. В нашем примере, кластер имеет адрес 10.10.10.20. Когда клиент обращается к сервису NFS, Samba или Postfix, он должен выполнять запрос по адресу 10.10.10.20. Heartbeat активирует этот IP адрес на той машине, где сейчас выполняется группа ресурсов.
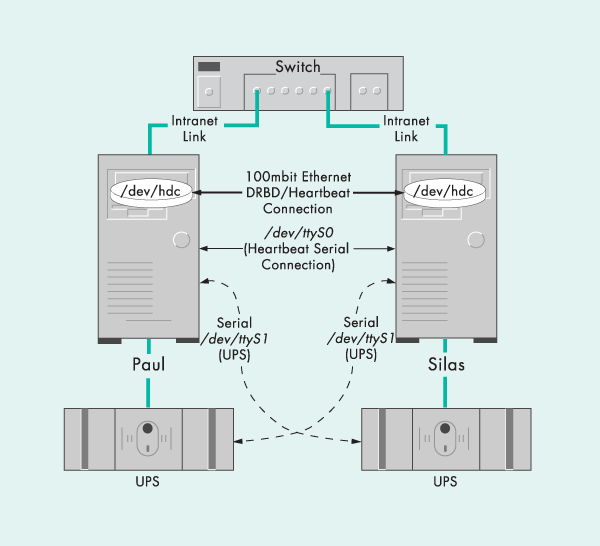
В обычном режиме функционирования кластера, показанном на рисунке 3, система paul предоставляет сервисы и IP адрес 10.10.10.20 (homeserver) принадлежит ей. При сбое компьютера paul, система silas перенимает IP-адрес homeserver и соответствующие сервисы. Если клиент попытается обратится к homeserver, когда paul не работает, ответит система silas. Эта ситуация изображена на рисунке 4. Итак мы разобрались с тем, как это все работает. Пора переходить непосредственно к установке и настройке.
Для работы кластера нам будут нужны: диски, сетевые карты для канала репликации, последовательный кабель и управляющие кабеля для ИБП.
Для функционирования кластера необходимо установить некоторые пакеты. Вам нужны: heartbeat-1.0.3, heartbeat-pils-1.0.3, heartbeat-stonith-1.0.3 и drbd-0.6.3. Все они доступны для SLES8 -- просто возьмите последние версии с сайта SuSE. Если вы работаете с другим дистрибутивом, загрузите необходимые пакеты с сайта http://linux-ha.org.
Установите пакеты с помощью rpm, yast2 или другим методом. Конечно, вы также должны установить все сервисы, которые вы хотите поддерживать. В нашем примере это: nfs-utils, samba, dhcp-base, dhcp-server, dhcp-tools и postfix.
Отредактируйте конфигурацию DRBD, расположенную в файле /etc/drbd.conf. В конфигурации присутствуют глобальные и локальные настройки. Убедитесь, что размеры дисков заданы верно.
Вот содержимое файл /etc/drbd.conf для нашего примера.
resource drbd0 {
protocol=C
fsckcmd=/bin/true
disk {
disk-size=80418208
do-panic
}
net {
sync-rate=8M # bytes/sec
timeout=60
connect-int=10
ping-int=10
}
on paul {
device=/dev/nb0
disk=/dev/hdc1
address=192.168.1.1
port=7789
}
on silas {
device=/dev/nb0
disk=/dev/hdc1
address=192.168.1.2
port=7789
}
}
Чтобы вычислить размер вашего диска, выполните команду blockdev getsize и разделите результат на 2. Если у вас получились разные результаты для систем, используйте меньшее значение.
Теперь создайте файловую систему на компьютере paul. Важно использовать журналируемую файловую систему и делать разделы одинакового размера.
Это означает, что вам будет необходимо выбрать одну из следующих ФС: Reiserfs, Ext3, JFS или XFS. И поскольку мы используем DRBD, лучше создавать файловую систему на устройстве /dev/nb0, а не уровнем ниже.
Вот команды, которые нужно выполнить на компьютере paul:
# /etc/init.d/drbd start
На запрос сделать систему paul первичной, ответьте "yes". Теперь нужно создать ФС и смонтировать её.
# mkfs -t reiserfs /dev/nb0; datadisk /dev/nb0 start
Наконец, если вы используете для синхронизации гигабитное соединение, измените параметр sync-rate, ограничивающий максимальную скорость ресинхронизации.
У Heartbeat есть три конфигурационных файлов: ha.cf содержит базовые настройки кластера; haresources содержит описания ресурсных групп и, наконец, authkeys обеспечивает настройку сетевой авторизации. Примеры конфигурационных файлов находятся в каталоге /usr/share/doc/packages/heartbeat, и описаны в документе "Getting Started" пакета Heartbeat. Все три файла должны присутствовать на обеих системах кластера.
Итак, в файле ha.cf определяются базовая конфигурация системы Heartbeat. Здесь указаны ноды кластера, способ протоколирования, задержки между пакетами "сердцебиения" и интервал, по истечению которого, не ответившая система считается вышедшей из строя ("dead time"). Вот файл /etc/ha.d/ha.cf для нашего кластера:
logfacility local7# syslog facility keepalive 1# интервал "сердцебиения" warntime 2# задержка "сердцебиения" deadtime 10# интервал, определяющий отказ другой ноды nice_failback on# node paul silas ping 10.10.10.254# адрес маршрутизатора bcast eth0 eth1# интерфейсы, сля посылки пакетов "сердцебиения" serial /dev/ttyS0# последовательное соединение для "сердцебиения" respawn /usr/lib/heartbeat/ipfail stonith_host paul apcsmart silas /dev/ttyS1 stonith_host silas apcsmart paul /dev/ttyS1
В этом примере, пакеты "сердцебиения" посылаются по интерфейсам eth0, eth1 и порту /dev/ttyS0. В нашем примере (и в большинстве других конфигураций), этот файл идентичен для всех нод. Как видно из конфигурационного файла, источники питания настроены как устройства типа "stonith". Что это такое, рассказывается во врезке "STONITH"
STONITH -- это акроним выражения "Shoot The Other Node In The Head" (застрелить другую ноду в голову -- прим.пер.) . Heartbeat использует эту технологию, для гарантии, что предположительно отказавший сервер не будет мешать работе кластера, а именно не повредит данные разделяемых дисков.
Если вы используете разделяемые диски, применение технологии STONITH обязательно. Иначе, какая-либо ошибка в конфигурации или программном обеспечении может спровоцировать ситуацию, когда каждая система считает, что другая нода вышла из строя. Эта ситуация называется расщеплением разума (split-brain). И если обе ноды одновременно смонтируют разделяемый диск, данные на нем будут разрушены. А это определенно плохо.
Существуют разные системы разделяемых дисков, такие как IBM ServeRAID, которые на аппаратном уровне гарантируют, что в один момент времени доступ к дискам может получить только один компьютер. В таких случаях применение STONITH не нужно.
Если вы используете DRBD, последствия расщепления разума не такие разрушительные и для некоторых приложений вы даже можете не обращать на них внимание. Следствием этого состояния является то, что обе ноды становятся первичными и начинают модифицировать свои копии данных отдельно друг от друга. К сожалению, обе системы "придут в себя", вам будет нужно уничтожить изменения на одной из систем. Если вас устраивает такой режим работы, то можно использовать кластер без технологии STONITH. Если же нет -- то нужно настраивать устройство STONITH.
Для получения списка поддерживаемых STONITH устройств, введите команду:
# /usr/sbin/stonith L
Для получения всей доступной информации по этим устройствам и их настройке, выполните:
# /usr/sbin/stonith h
Теперь рассмотрим файл /etc/ha.d/haresources:
paul 10.10.10.20 \ datadisk::drbd0 \ nfslock nfsserver nmb smb \ dhcpd postfix
Эта конфигурация определяет одну группу ресурсов, которая номинально принадлежит системе paul, и состоит из IP адреса 10.10.10.20, ресурса datadisk (DRBD) для устройства drbd0, и процессов NFS, Samba, dhcpd и Postfix. Heartbeat использует нотацию :: для разделения аргументов, передаваемых init скриптам. (Это основное отличие между скриптами Heartbeat и обычными системными init-скриптами.)
Где же находятся эти скрипты? IPaddr и datadisk находятся в каталоге /etc/ha.d/resource.d/. Остальные скрипты находятся в стандартном места: каталоге /etc/init.d/.
Heartbeat умеет управляться с большинством сервисов, у которых есть свои init-скрипты. Однако, имена скриптов должны быть одинаковыми на всех нодах кластера. (Имена скриптов обычна разнятся от дистрибутива к дистрибутиву, потому использование одного дистрибутива на всех серверах облегчает настройку и сопровождение.)
Перейдем теперь к файлу /etc/ha.d/authkeys:
auth 1 1 sha1 RandomPasswordfc970c94efb
Это самый простой из всех конфигурационных файлов. Он содержит метод авторизации (sha1) и ключ для подписи пакетов. Файл одинаков для всех серверов кластера и должен быть доступен по чтению только пользователю root.
За запуск сервисов одновременно и Heartbeat и init отвечать не могут. Потому запретите запуск сервисов nfslock, nfsserver, nmb, smb, dhcpd и postfix при загрузке. Это делается командой:
# chkconfig --del nfslock nfsserver \ nmb smb dhcpd postfix
Кроме того, убедитесь что раздел /home размонтирован и не монтируется автоматически при помощи файла /etc/fstab. Если в файле fstab существует запись для файловой системы /home, удалите ее. И добавьте следующую:
/dev/nb0 /home reiserfs noauto 0 0
Если раздел /home был смонтирован, размонтируйте его.
С большинством приложений удобнее работать, указывая символьные имена вместо IP-адресов. Если в вашей сети используется файл /etc/hosts, вам будет нужно добавить в него нечто вроде:
10.10.10.20 homeserver # HA services
Если вы применяете систему DNS, внесите необходимые изменения в ее конфигурацию. После этого клиенты смогут добавить в свой файл /etc/fstab запись:
homeserver:/home /home nfs \ defaults 0 0
Некоторые сервисы должны хранить свои данные на реплицируемом диске. Также удобно поместить на разделяемый диск как можно больше конфигурационных файлов сервисов высокой готовности. В этом случае будет существовать лишь одна копия конфигурационных файлов, а вы исключите ситуацию, когда изменения проведенные на одном сервере, забывают продублировать на втором.
Создадим каталог /home/HA-config/. В нем будут хранится некоторые конфигурационные файлы из каталогов /etc/ и /var/. Перенесем в /home/HA-config/etc/ следующие данные
А в каталоге /etc/ создадим на них символьные ссылки.
Повторим эту операцию для каталогов /var/lib/dhcp/, /var/lib/nfs/, /var/lib/samba/, /var/spool/mail/ и /var/spool/postfix/, которые скопируем соответственно в /home/HA-config/var/. Идея состоит в том, чтобы сервисы использовали конфигурационные данные, которые реплицируются по всему кластеру, а не хранящиеся на локальном диске.
Размонтируйте /home следующим образом:
# datadisk /dev/nb0 stop # /etc/init.d/drbd stop
Сервисам часто требуется сообщить IP-адрес, который они должны использовать. Для сервиса nfslock необходимо указать программе /sbin/rpc.statd адрес, на котором будут сообщаться о блокировках NFS. Это делается указанием параметра n homeserver в вызове rpc.statd, который находится в файле /etc/init.d/nfslock. Для сервиса Samba нужно добавить параметр interfaces в секцию [global] файла /etc/samba/smb.cf:
interfaces = 127.0.0.1/8 10.10.10.20/24
Наконец, укажем Postfix обслуживать запросы на нужных интерфейсах. Для этого в файле /etc/postfix/main.cf добавим строку:
inet_interfaces = 127.0.0.1, 10.10.10.20
Вне зависимости от того насколько хорошо вы разбираетесь в сервисах, настройке DRBD или Heartbeat, вам нужно проверить вашу систему высокой готовности. Чем тщательней вы её оттестируете, тем больше вы будете знать о её работе, и тем надежнее будет ваш результат. Плохо проверенная система ВГ не является таковой. (Хорошее тестирование ВГ представляет собой тему для отдельной статьи.)
При использовании DRBD, вы доверяете ей репликацию данных. Этот компонент системы также важен как диски, и код файловой системы. Давайте на некоторое время запретим автоматический запуск DRBD и Heartbeat:
# chkconfig --set drbd off # chkconfig --set heartbeat off
Не забудьте выполнить эти команды на обеих системах. Перезагрузите сервера. После загрузки, на машине silas выполните:
# /etc/init.d/drbd start
Теперь на системе paul:
# /etc/init.d/drbd start
После этого, на консоли системы silas должны появится дальнейшие сообщения. Теперь можно проверить, что DRBD сделал систему paul основной, а silas -- вторичной, выполнив команду на компьютере paul:
# cat /proc/drbd
Вы должны будете увидеть примерно следующее:
0: cs:SyncingAll st:Primary/Secondary
Это означает, что все запустилось корректно и сейчас выполняется полная синхронизация. Если вы используете 100 Мбитное соединение и большие диски, это займет некоторое время. Наблюдать прохождение синхронизации можно в файле /proc/drbd.
Дождитесь завершения синхронизации.
Выполните в системе paul команду /etc/init.d/heartbeat start. Она запускает сервис Heartbeat и выдает множество сообщение в системный лог /var/log/messages. Чтобы проверить, что все работает правильно, выполните следующие команды:
# mount | grep /home # ifconfig | grep 10.10.10.20 # /etc/init.d/nfslock status # /etc/init.d/nfsserver status # /etc/init.d/nmb status # /etc/init.d/smb status # /etc/init.d/dhcpd status # /etc/init.d/postfix status
/home должен быть смонтировать, IP-адрес быть 10.10.10.20, а все сервисы -- запущены.
После этого запустите Heartbeat на другой ноде. Запуск Heartbeat будет аналогичен процессу на первой ноде, кроме запуска сервисов.
Чтобы заставить Heartbeat перенести сервисы с системы paul на silas, нужно зарегистрироваться в системе paul и выполнить команду:
# /usr/sbin/heartbeat/hb_standby
После этого Heartbeat быстро перенесет весь набор сервисов на систему silas. Весь процесс должен занять около 15 секунд. После этого зарегистрируйтесь в системе silas, проверьте логи и убедитесь что все сервисы работают. Затем выполните команду hb_standby на silas, чтобы перенести сервисы обратно на paul. Проверьте системные логи paul на предмет корректного переноса сервисов.
Поскольку мы указали в файле ha.cf директиву ping, Heartbeat послушно "пингует" маршрутизатор с каждой из нод раз в секунду. Кроме того, мы задали выполнение ipfail, который наблюдает за результатами пингования и определяет, какая из машин имеет лучшее соединение.
На этом этапе ваши сервисы должны выполняться на paul. Для проверки ipfail отсоедините кабель от интерфейса eth0 системы paul; все ресурсы кластера должны смигрировать на silas. Восстановив сетевое подключение paul и отсоединив silas, сервисы вернутся назад.
Перейдем к более серьезным тестам -- отказу системы. Если вы выполняли все предыдущее тесты, то все сервисы у вас должны выполнятся на системе paul. Выполните следующие команды на обеих системах. Они обеспечат автоматический запуск Heartbeat и DRBD при загрузке:
# chkconfig heartbeat 35 # chkconfig drbd 35
После этого нажмите кнопку reset системы silas. После её перезагрузки запустится быстрая синхронизация с системой paul, которая должна будет завершиться в течении нескольких секунд. По завершении процесса синхронизации нажмите reset компьютера paul. Сервисы должны будут смигрировать на систему silas приблизительно в течении десяти секунд.
Создание, настройка и тестирование систем высокой готовности -- это интересное и сложное занятие, которое мы слегка осветили в этой статье. Тем не менее, как можно заметить за стоимость последовательного кабеля, нескольких сетевых карт и дисков, а также небольшого количества вашего времени, вы можете создать эффективный кластер высокой готовности, всего лишь из двух машин. Прочитайте документацию к пакетам Heartbeat и DRBD, и присоединяйтесь к спискам рассылки Linux-HA и DRBD, чтобы узнать больше о кластерах высокой готовности. Домашняя страница проекта Linux-HA расположена по адресу http://linux-ha.org.